CLEVRER: CoLlision Events for Video REpresentation and Reasoning
Kexin Yi* Chuang Gan* Yunzhu Li Pushmeet Kohli Jiajun Wu
Antonio Torralba Joshua B. Tenenbaum
Abstract:
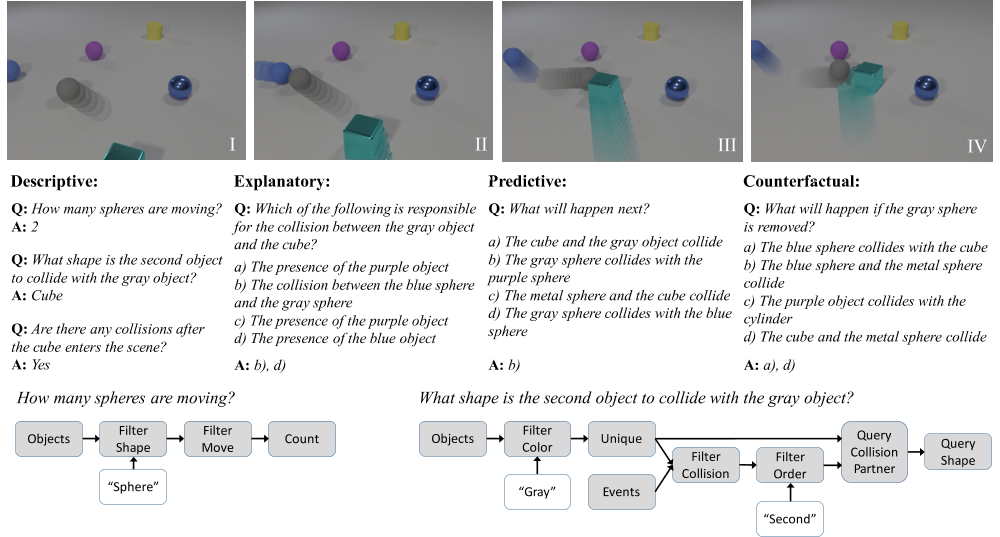
The ability to reason about temporal and causal events from videos lies at the core of human intelligence. Most video reasoning benchmarks, however, focus on pattern recognition from complex visual and language input, instead of on causal structure. We study the complementary problem, exploring the temporal and causal structures behind videos of objects with simple visual appearance. To this end, we introduce the CoLlision Events for Video REpresentation and Reasoning (CLEVRER), a diagnostic video dataset for systematic evaluation of computational models on a wide range of reasoning tasks. Motivated by the theory of human casual judgment, CLEVRER includes four types of question: descriptive (e.g., “what color"), explanatory (”what’s responsible for"), predictive (”what will happen next"), and counterfactual (“what if"). We evaluate various state-of-the-art models for visual reasoning on our benchmark. While these models thrive on the perception-based task (descriptive), they perform poorly on the causal tasks (explanatory, predictive and counterfactual), suggesting that a principled approach for causal reasoning should incorporate the capability of both perceiving complex visual and language inputs, and understanding the underlying dynamics and causal relations. We also study an oracle model that explicitly combines these components via symbolic representations.
Paper:
CLEVRER: CoLlision Events for Video REpresentation and Reasoning
Kexin Yi*, Chuang Gan*, Yunzhu Li, Pushmeet Kohli, Jiajun Wu, Antonio Torralba, Joshua B. Tenenbaum
ICLR, 2020 (* indicates equal contributions)
[PDF] [MIT Technology Review] [WIRED] [Venturebeat]
Kexin Yi*, Chuang Gan*, Yunzhu Li, Pushmeet Kohli, Jiajun Wu, Antonio Torralba, Joshua B. Tenenbaum
ICLR, 2020 (* indicates equal contributions)
[PDF] [MIT Technology Review] [WIRED] [Venturebeat]
Dataset
Related Publications
Neural-Symbolic VQA: Disentangling Reasoning from Vision and Language Understanding
Kexin Yi*, Jiajun Wu*, Chuang Gan, Antonio Torralba, Pushmeet Kohli, and Joshua B. Tenenbaum
NeurIPS, 2018 (* indicates equal contributions)
Kexin Yi*, Jiajun Wu*, Chuang Gan, Antonio Torralba, Pushmeet Kohli, and Joshua B. Tenenbaum
NeurIPS, 2018 (* indicates equal contributions)